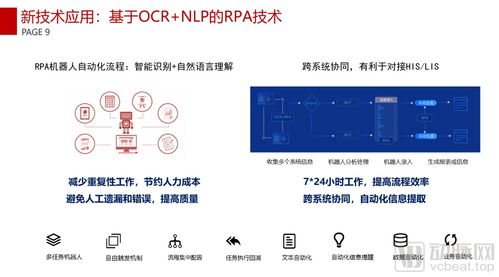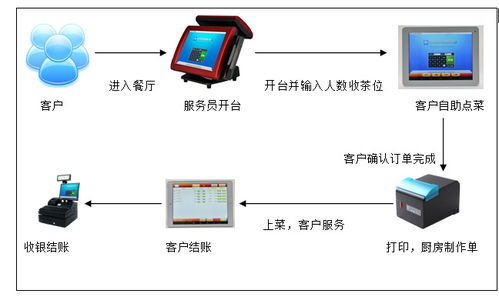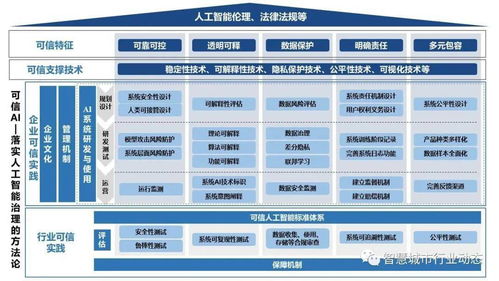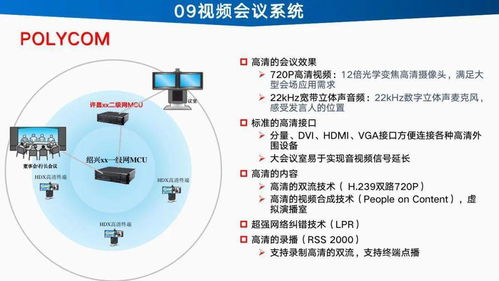
随着人工智能技术的快速发展,大规模数据处理与高性能计算已成为智能应用落地的关键支撑。在人工智能基础软件开发中,有效整合大数据处理与高性能计算能够显著提升模型训练效率和系统响应能力。以下是四个关键实现步骤,及其在人工智能基础软件开发中的具体应用。
第一步:高效数据采集与预处理
在人工智能开发中,高质量的数据是模型准确性的基础。通过分布式数据采集工具(如Apache Kafka或Flink)实时收集多源异构数据,包括图像、文本和传感器数据。然后,利用高性能计算集群对数据进行并行清洗、去噪和特征提取,例如使用Apache Spark进行内存计算加速。这一步骤不仅减少了数据冗余,还通过预处理流水线为后续模型训练提供标准化的输入,显著缩短了人工智能模型的数据准备时间。
第二步:分布式存储与资源管理
为应对海量数据存储需求,采用分布式文件系统(如HDFS)或对象存储(如Amazon S3),确保数据高可用性和可扩展性。利用资源管理框架(如Kubernetes或YARN)动态分配计算资源,支持多任务并发执行。在人工智能开发中,这允许团队同时运行多个模型训练任务,并优化GPU/CPU利用率,从而提高开发迭代速度。例如,在深度学习场景中,通过容器化部署模型训练环境,实现资源隔离和弹性伸缩。
第三步:并行算法设计与计算优化
针对人工智能算法的高计算复杂度,设计并行计算模型是关键。使用MPI(消息传递接口)或CUDA等框架,将机器学习任务(如神经网络训练)分解为子任务,并在多节点或GPU上并行执行。例如,在开发自然语言处理模型时,通过数据并行或模型并行策略加速Transformer架构的训练过程。结合编译器优化(如TVM)和硬件加速(如FPGA),进一步提升计算性能,降低人工智能基础软件的延迟。
第四步:智能调度与结果集成
通过智能调度系统(如Apache Airflow)协调数据处理与计算流程,确保任务依赖性和优先级管理。在人工智能应用中,这包括自动化模型训练、评估和部署流水线。计算结果通过API或分布式数据库(如Redis)集成到最终应用中,支持实时推理和反馈循环。例如,在开发推荐系统时,高性能计算处理用户行为数据后,模型结果被快速推送到线上服务,实现低延迟个性化推荐。
这四个步骤形成了一个闭环流程:从数据准备到智能调度,不仅提升了大数据处理的效率,还直接赋能人工智能基础软件的开发,使其能够应对复杂场景下的高性能需求。随着硬件和算法的进步,这一流程将进一步优化,推动人工智能技术的广泛应用。